大家好,我是小寒。
今天给大家分享一个超强的算法模型,Transformer
Transformer 模型是深度学习中一种基于注意力机制的模型,广泛应用于自然语言处理(NLP)任务,如机器翻译、文本生成和问答系统。
它由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出,突破了传统序列模型(如RNN和LSTM)的限制,特别是在长距离依赖问题上表现出色。它是 ChatGPT 和所有其他 LLM 的支柱。
https://arxiv.org/pdf/1706.03762

模型架构
Transformer 模型由编码器(Encoder)和解码器(Decoder)组成。编码器和解码器各由 N 层相同的子层堆叠而成。
以下是编码器和解码器的详细结构。
编码器(Encoder)
每层编码器包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Neural Network)
解码器(Decoder)
每层解码器包含三个子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 编码器-解码器注意力机制(Encoder-Decoder Attention)
- 前馈神经网络(Feed-Forward Neural Network)
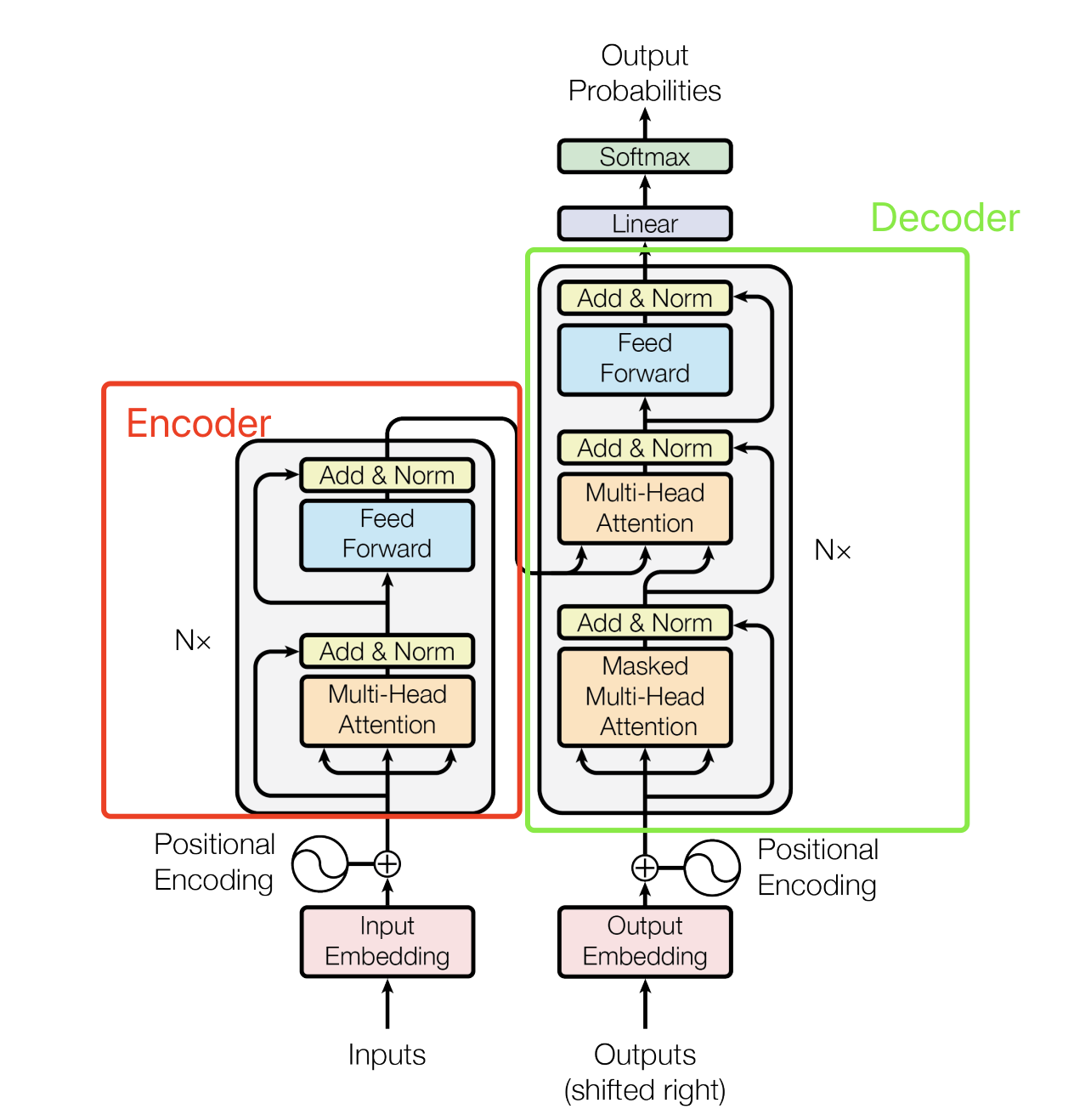
Transformer 核心组件
下面,让我们来看看 Transformer 如何将输入文本序列转换为向量表示,又如何逐层处理这些向量表示得到最终的输出。
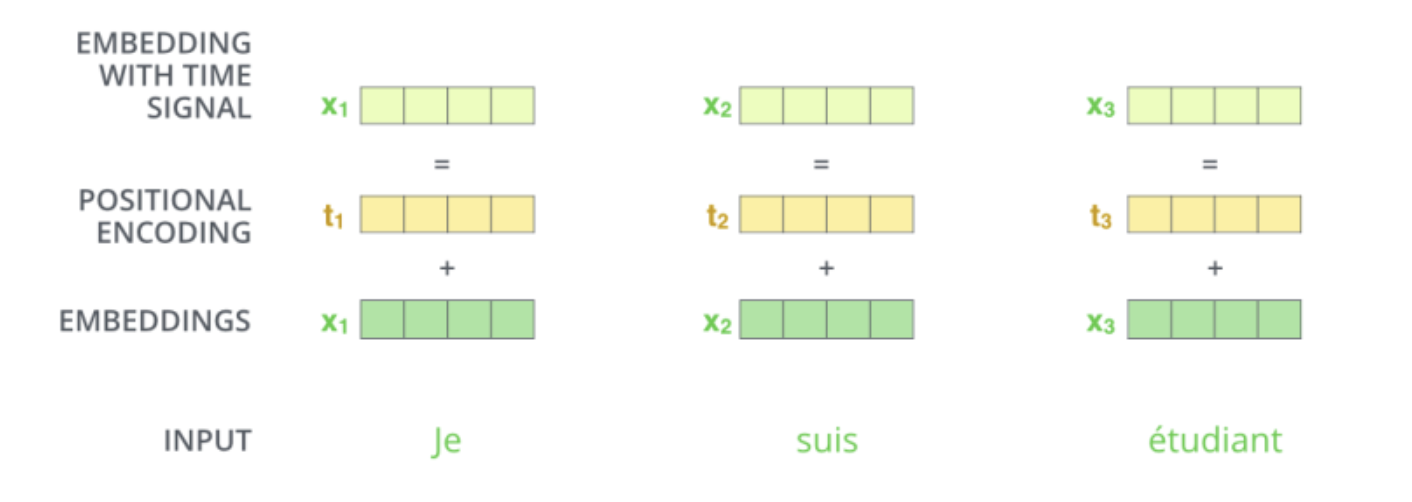
1.输入编码
和常见的 NLP 任务一样,我们首先会使用词嵌入算法(word embedding),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维。但为了简化起见,我们这里使用 4 维的词向量来进行讲解。
如下图所示,假设我们的输入文本是序列包含了 3 个词,那么每个词可以通过词嵌入算法得到一个 4 维向量,于是整个输入被转化成为一个向量序列。

2.位置编码
由于 Transformer 模型依赖于自注意力机制,而自注意力机制本质上是无序的,即它不区分输入序列中各个词的位置顺序,因此需要显式地引入位置信息来帮助模型理解序列的顺序关系。
位置编码的具体实现方式有多种,Transformer 模型中采用了一种基于正弦和余弦函数的方式。
对于输入序列中的每个位置 pos 和每个维度 i,位置编码向量的计算公式如下。
其中:
- pos 表示序列中词语的位置。
- i 表示位置编码向量的维度索引。
- \(d_{model}\) 是词嵌入向量的维度。
在模型中,位置编码向量会与输入嵌入向量相加,将位置信息显式地引入到输入数据中。
下面是在 python 中实现位置编码的示例代码。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# Compute positional encodings
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(
torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + x + self.pe[:, :x.size(1)]
return x
# Example usage
d_model = 512
max_len = 100
num_heads = 8
# Positional encoding
pos_encoder = PositionalEncoding(d_model, max_len)
# Example input sequence
input_sequence = torch.randn(5, max_len, d_model)
# Apply positional encoding
input_sequence = pos_encoder(input_sequence)
print("Positional Encoding of input sequence:")
print(input_sequence.shape)
3. 编码器 encoder
输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第1层编码器,第1层编码器输出的同样是一个向量序列,再接着送入下一层编码器:第1层编码器的输入是融合位置向量的词向量,更上层编码器的输入则是上一层编码器的输出。
下图展示了向量序列在单层 encoder 中的流动,融合位置信息的词向量进入self-attention 层,self-attention 输出每个位置的向量再输入 FFN 神经网络得到每个位置的新向量。
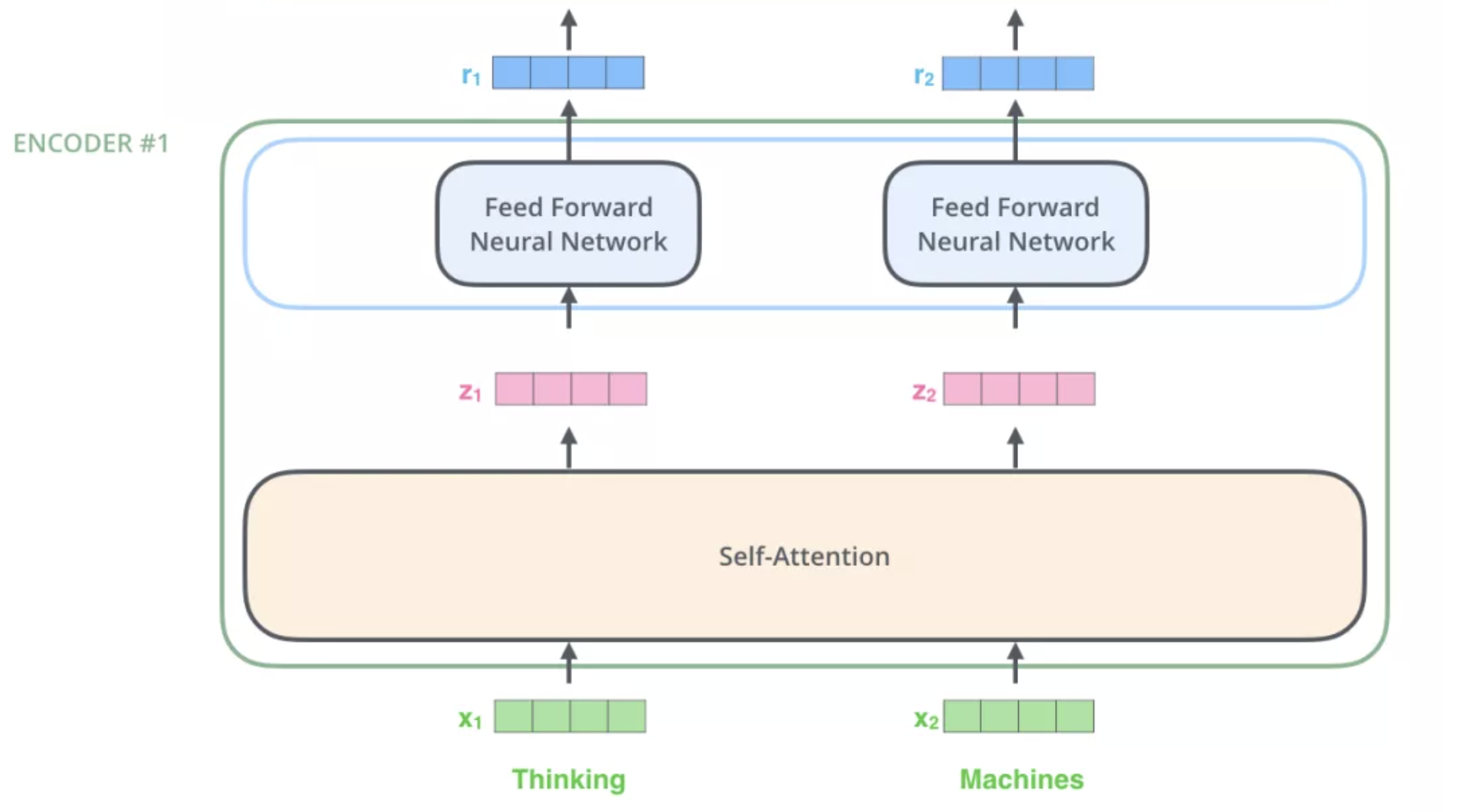
Self-Attention
注意力机制是神经网络中一个非常吸引人的概念,尤其是在 NLP 等任务中。它就像给模型打了一盏聚光灯,让它专注于输入序列的某些部分,而忽略其他部分,就像我们人类在理解句子时会注意特定的单词或短语一样。
现在,让我们深入研究一种特殊的注意力机制,称为 Self-Attention (自注意力)。想象一下,你正在阅读一个句子,你的大脑会自动突出显示重要的单词或短语以理解其含义。这本质上就是自注意力在神经网络中的作用。它使序列中的每个单词能够 “注意” 其他单词(包括它自己),以更好地理解上下文。
Self-Attention 的工作原理
- 计算 Query、Key 和 Value 向量
给定输入序列 X,通过三个不同的线性变换得到 Query(查询向量) 、Key(键向量) 和Value(值向量)。
\(\(Q=XW_Q,K=XW_K,V=XW_V\)\)
其中,\(W_Q, W_K, W_V\)是可训练的权重矩阵。
- 计算注意力得分
通过点积计算 Query 和 Key 之间的相似度,再通过缩放(scaling)以稳定梯度。
\(\(\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\)\)
其中,\(d_k\) 是 Key 向量的维度。
下面,我们通过一个具体的案例进行说明。假设,我们需要对词组 Thinking Machines 进行翻译,其中 Thinking 对应的 embedding 向量用 \(x_1\) 表示,Machines 对应的 embedding 向量用 \(x_2\) 表示。
当我们处理 Thinking 这个词时,我们需要计算句子中所有词与它的 Attention Score。首先将当前词作为搜索的 query,去和句子中所有词(包含该词本身)的 key 去匹配,看看相关度有多高。我们用 q1代表 Thinking 对应的 query 向量,k1 及 k2 分别代表 Thinking 以及Machines 对映的 key 向量,则计算 Thinking 的 attention score 的时候我们需要计算 q1 与 k1、k2 的点乘,同理,我们计算 Machines的 attention score 的时候需要计算 q2 与 k1、k2 的点乘。
如下图中所示我们分别得到了q1与k1、k2的点乘积,然后我们进行尺度缩放与softmax归一化。
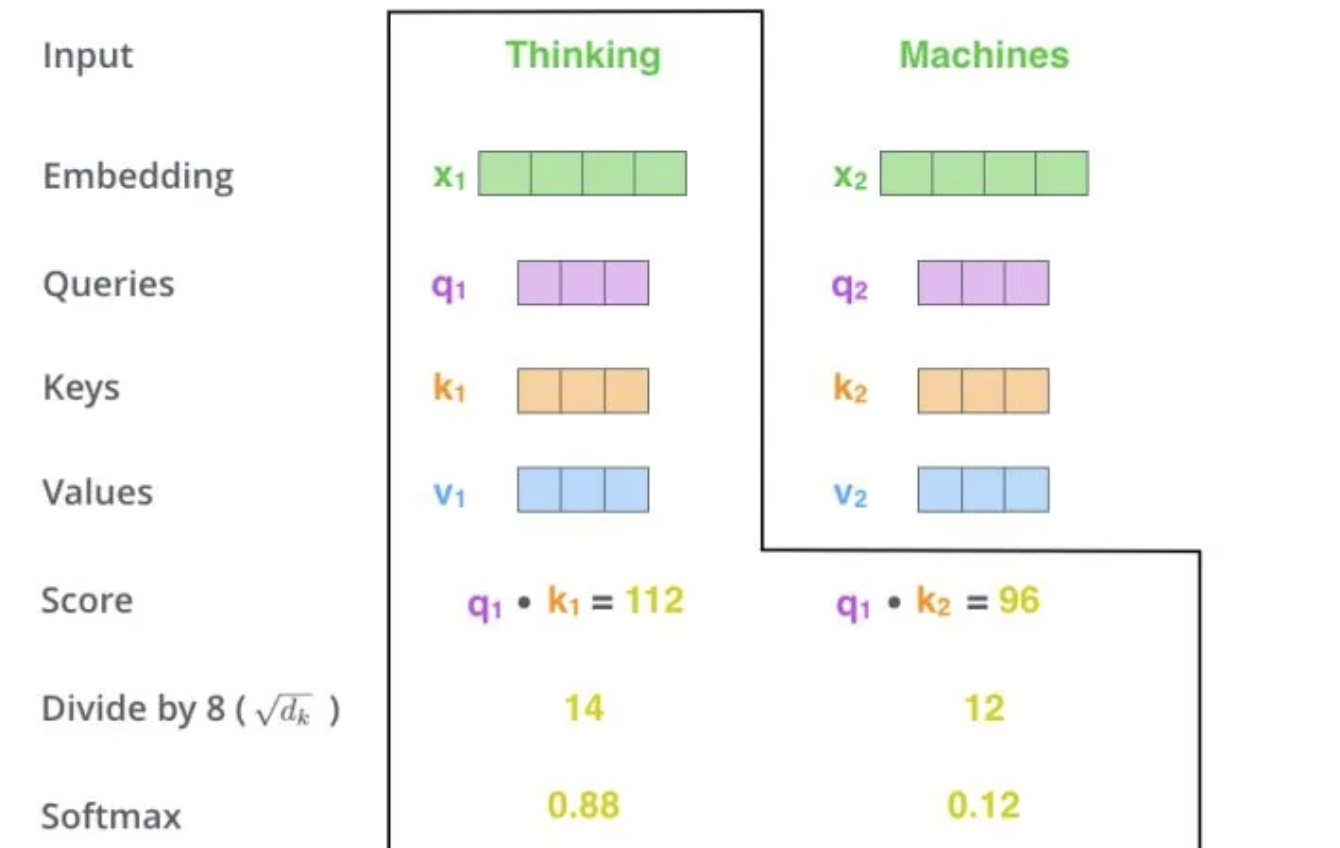
显然,当前单词与自身的注意力得分一般最大,其他单词根据当前单词重要程度有相应的分数。随后我们用这些注意力得分与 Value 向量相乘,得到加权的向量。
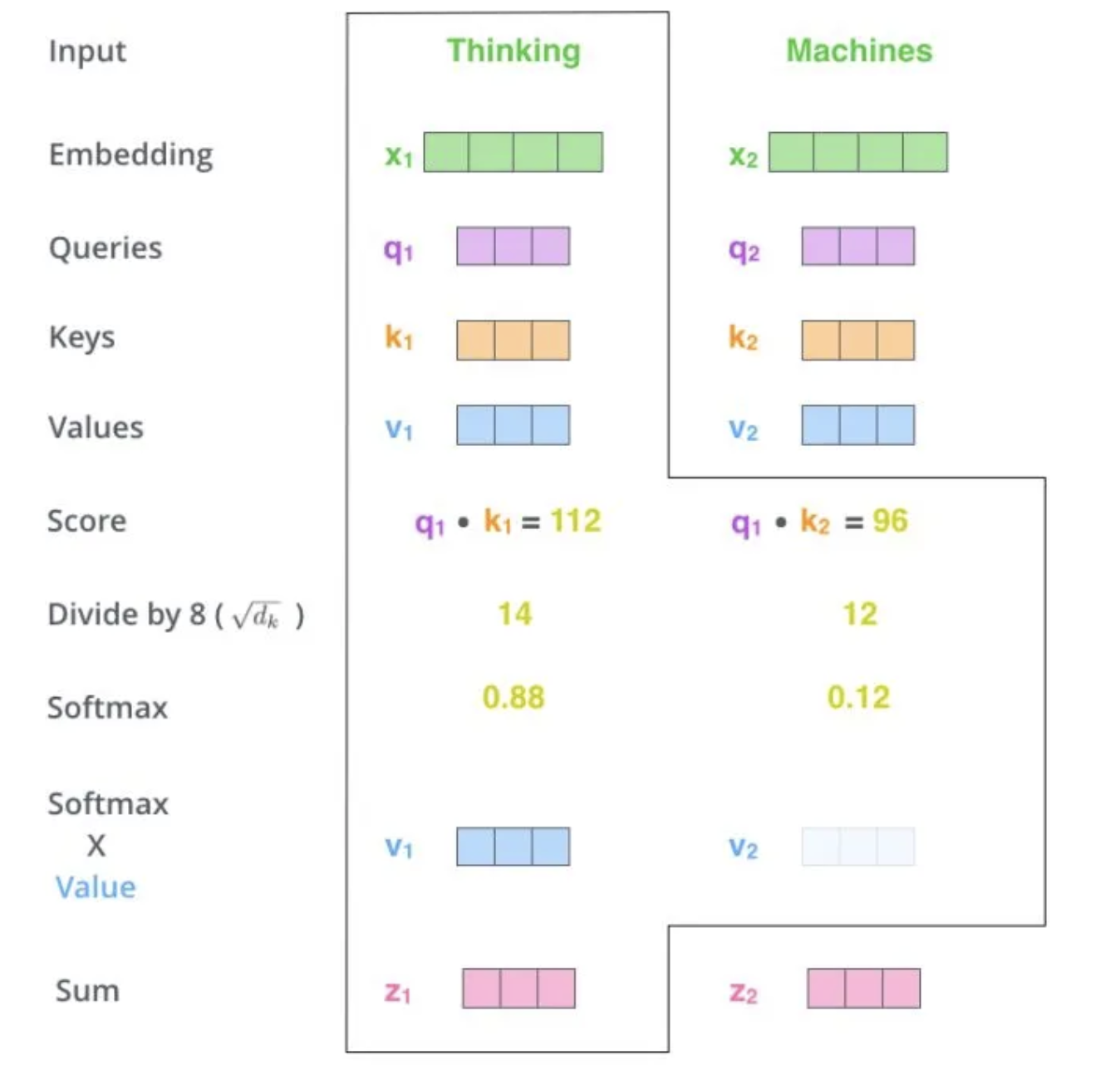
上图中 \(z_1\) 表示对第一个位置词向量(Thinking)计算 Self Attention 的全过程。最终得到的当前位置(这里的例子是第一个位置)词向量会继续输入到前馈神经网络。
在实际的代码实现中,Self Attention 的计算过程是使用矩阵快速计算的,一次就得到所有位置的输出向量。
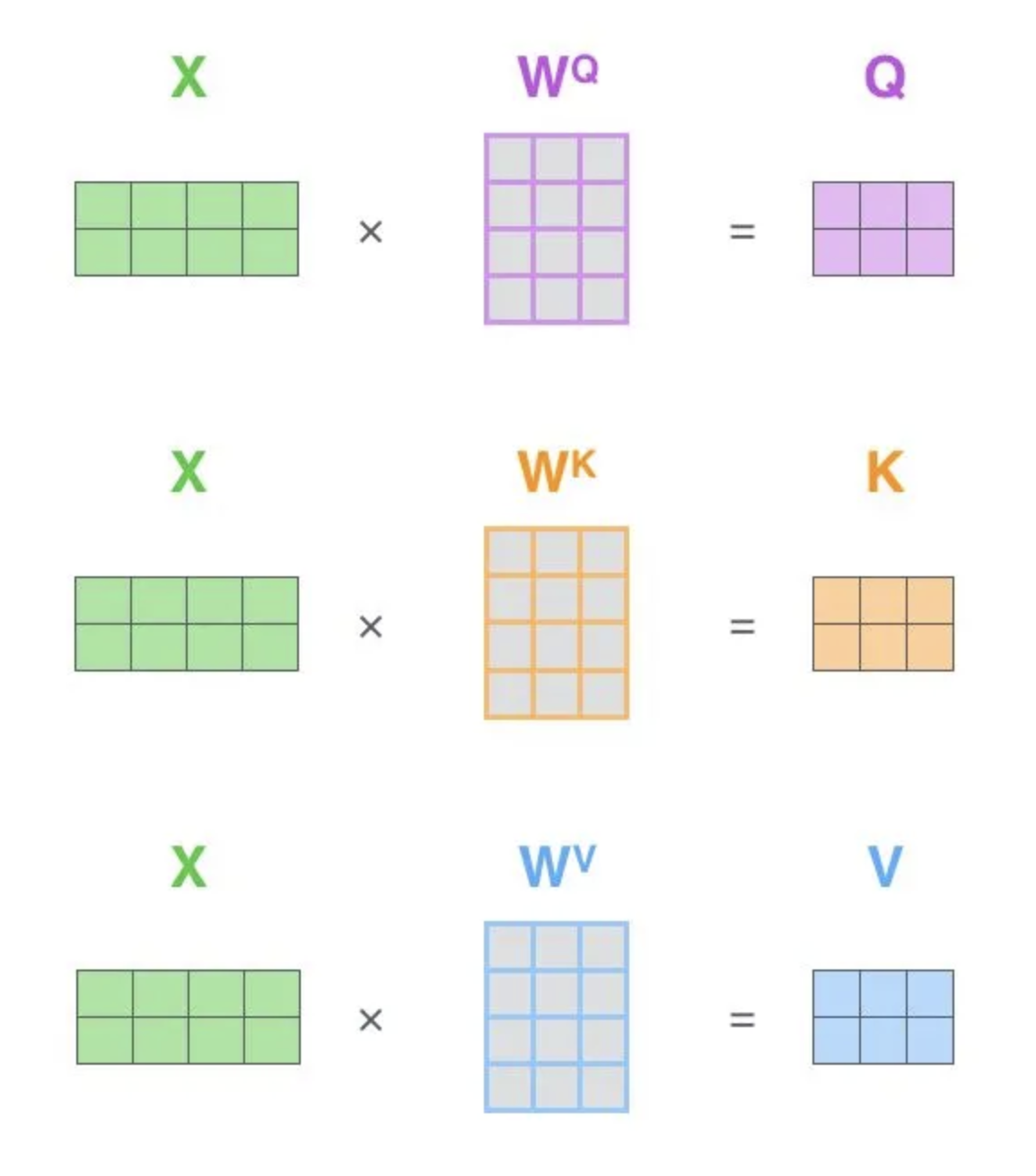
其中 \(\(w^q, w^k, w^v\)\) 是我们模型训练过程中学习到的合适的参数。
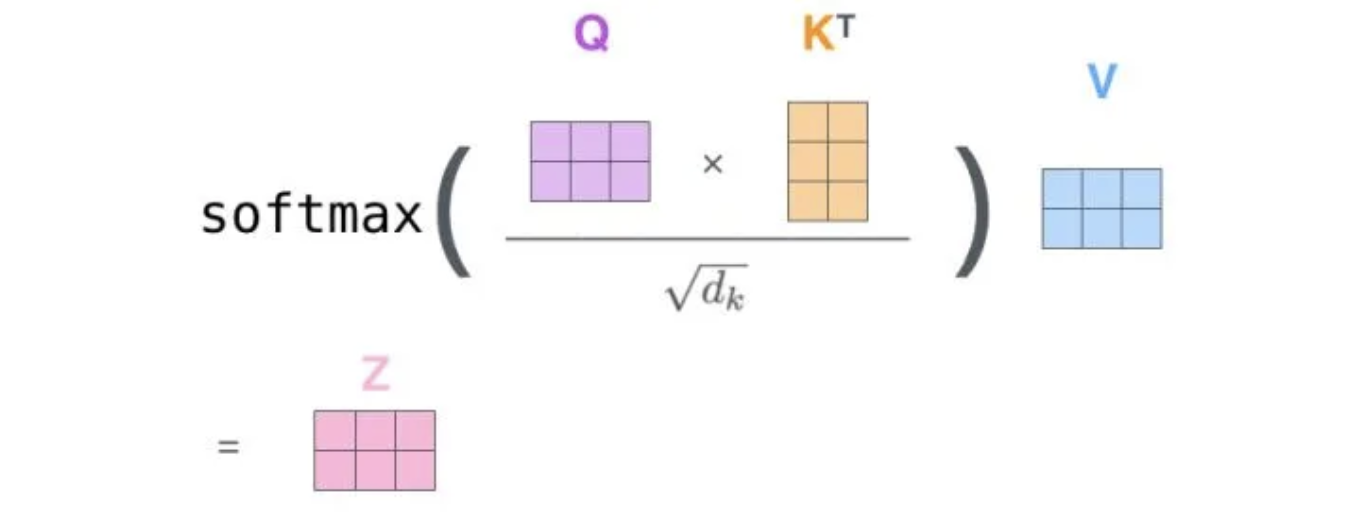
接下来,让我们看看在代码中如何实现。
import torch
import torch.nn.functional as F
# Example input sequence
input_sequence = torch.tensor([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6], [0.7, 0.8, 0.9]])
# Generate random weights for Key, Query, and Value matrices
random_weights_key = torch.randn(input_sequence.size(-1), input_sequence.size(-1))
random_weights_query = torch.randn(input_sequence.size(-1), input_sequence.size(-1))
random_weights_value = torch.randn(input_sequence.size(-1), input_sequence.size(-1))
# Compute Key, Query, and Value matrices
key = torch.matmul(input_sequence, random_weights_key)
query = torch.matmul(input_sequence, random_weights_query)
value = torch.matmul(input_sequence, random_weights_value)
# Compute attention scores
attention_scores = torch.matmul(query, key.T) / torch.sqrt(torch.tensor(query.size(-1),
dtype=torch.float32))
# Apply softmax to obtain attention weights
attention_weights = F.softmax(attention_scores, dim=-1)
# Compute weighted sum of Value vectors
output = torch.matmul(attention_weights, value)
print("Output after self-attention:")
print(output)
而多头注意力(Multi-Head Attention)就是我们可以有不同的 Q,K,V 表示,之后再将其结果合并起来,如下图所示。

下面是多头注意力的代码实现。
# Code implementation of Multi-Head Attention
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0
self.depth = d_model // num_heads
# Linear projections for query, key, and value
self.query_linear = nn.Linear(d_model, d_model)
self.key_linear = nn.Linear(d_model, d_model)
self.value_linear = nn.Linear(d_model, d_model)
# Output linear projection
self.output_linear = nn.Linear(d_model, d_model)
def split_heads(self, x):
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.depth).transpose(1, 2)
def forward(self, query, key, value, mask=None):
# Linear projections
query = self.query_linear(query)
key = self.key_linear(key)
value = self.value_linear(value)
# Split heads
query = self.split_heads(query)
key = self.split_heads(key)
value = self.split_heads(value)
# Scaled dot-product attention
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.depth)
# Apply mask if provided
if mask is not None:
scores += scores.masked_fill(mask == 0, -1e9)
# Compute attention weights and apply softmax
attention_weights = torch.softmax(scores, dim=-1)
# Apply attention to values
attention_output = torch.matmul(attention_weights, value)
# Merge heads
batch_size, _, seq_length, d_k = attention_output.size()
attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size,
seq_length, self.d_model)
# Linear projection
attention_output = self.output_linear(attention_output)
return attention_output
# Example usage
d_model = 512
max_len = 100
num_heads = 8
d_ff = 2048
# Multi-head attention
multihead_attn = MultiHeadAttention(d_model, num_heads)
# Example input sequence
input_sequence = torch.randn(5, max_len, d_model)
# Multi-head attention
attention_output= multihead_attn(input_sequence, input_sequence, input_sequence)
print("attention_output shape:", attention_output.shape)
残差连接和层标准化
经过 Multi-head Attention 后会进入 Add & Norm 层,这一层是指残差连接和层标准化。

前一层的输出 \(Sublayer(x)\) 会与原输入 x 相加(残差连接),以减缓梯度消失的问题,然后再做层标准化。
其中,Sublayer(x) 表示 Multi-head Attention 的输出。
下面,我们来看一下什么是层标准化,和批量标准化有什么区别。
批量标准化是对一个批次中的所有样本进行标准化处理,它是对一个批次中的所有样本的每一个特征进行归一化。而层标准化是对每个样本的所有特征进行标准化处理,独立于同一批次中的其他样本。
层标准化的优点是不受批量大小的影响,可以在小批量甚至单个样本上工作。更适合序列数据。

前馈网络 (FFN)
接着进入到 FFN 层,由下列公式可以看到输入x 先做线性运算后,然后送入 ReLU,之后再做一次线性运算。
其中,\(W_1\), \(W_2\) 和 \(b_1\), \(b_2\) 是可训练的权重和偏置项。
在 FFN 后面,也会接一个 Add & Norm 层,这里就不再赘述。
下面是用 python 实现前馈网络。
# code implementation of Feed Forward
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(FeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.linear1(x))
x = self.linear2(x)
return x
# Example usage
d_model = 512
max_len = 100
num_heads = 8
d_ff = 2048
# Multi-head attention
multihead_attn = MultiHeadAttention(d_model, num_heads)
# Feed-forward network
ff_network = FeedForward(d_model, d_ff)
# Example input sequence
input_sequence = torch.randn(5, max_len, d_model)
# Multi-head attention
attention_output= multihead_attn(input_sequence, input_sequence, input_sequence)
# Feed-forward network
output_ff = ff_network(attention_output)
print('input_sequence',input_sequence.shape)
print("output_ff", output_ff.shape)
到此为止,我们的编码器模块已经介绍完美。
接下来,我们将上述代码进行整合。下面的代码是实现编码器的整体 python 代码。
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# Self-attention layer
attention_output= self.self_attention(x, x,
x, mask)
attention_output = self.dropout(attention_output)
x = x + attention_output
x = self.norm1(x)
# Feed-forward layer
feed_forward_output = self.feed_forward(x)
feed_forward_output = self.dropout(feed_forward_output)
x = x + feed_forward_output
x = self.norm2(x)
return x
d_model = 512
max_len = 100
num_heads = 8
d_ff = 2048
# Multi-head attention
encoder_layer = EncoderLayer(d_model, num_heads, d_ff, 0.1)
# Example input sequence
input_sequence = torch.randn(1, max_len, d_model)
# Multi-head attention
encoder_output= encoder_layer(input_sequence, None)
print("encoder output shape:", encoder_output.shape)
4.解码器 Decoder
现在我们已经介绍了编码器中的大部分概念,我们也基本知道了编码器的原理。现在让我们来看下, 编码器和解码器是如何协同工作的。
编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量,这组序列向量会作为解码器的 K、V 输入,其中 K=V=解码器输出的序列向量表示。这些注意力向量将会输入到每个解码器的 Encoder-Decoder Attention 层,这有助于解码器把注意力集中到输入序列的合适位置,如下图所示。

解码(decoding )阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译),解码器当前时间步的输出又重新作为下一个时间步解码器的输入。然后重复这个过程,直到输出一个结束符。如下图所示。

下面,我们来关注一下解码器中包含的核心组件。
Decoder 与 Encoder 一样会先跟 Positional Encoding 相加再进入 layer,不同的是 Decoder 有三个子层 Masked Multi-head Attention、Multi-head Attention、Feed Forward。此外,中间层 Multi-head Attention 的输入 q 来自于本身前一层的输出,而 k, v 则是来自于Encoder 的输出。
下面我们来重点介绍一下 Masked Multi-head Attention 和 Multi-head Attention。
Masked Multi-head Attention
在标准的多头注意力机制中,每个位置的查询(Query)会与所有位置的键(Key)进行点积计算,得到注意力分数,然后与值(Value)加权求和,生成最终的输出。然而,在解码器中,生成序列时不能访问未来的信息。因此需要使用掩码(Mask)机制来屏蔽掉未来位置的信息。
例如在 “我看到 ______ 追着一只老鼠” 中,我们会直观地填充猫,因为这是最有可能的。因此,在编码单词时,它需要知道整个句子中的所有内容。这就是为什么在自注意力层中,查询是针对所有单词执行的。但是在解码时,当试图预测句子中的下一个单词时,从逻辑上讲,它不应该知道我们试图预测的单词之后有哪些单词。因此需要使用掩码(Mask)机制来屏蔽掉未来位置的信息。
掩码机制通过引入一个上三角矩阵来屏蔽未来的位置。具体来说,对于每个查询位置 t,只允许它与 t 及其之前的位置进行注意力计算,而屏蔽掉 t 之后的位置。这可以通过在计算注意力分数时将未来位置的分数设置为负无穷来实现,从而在 softmax 函数中得到接近于零的权重。

Multi-head Attention
在解码器中的 Multi-head Attention 也叫做 Encoder-Decoder Attention,它的 Query 来自解码器的 self-attention,而 Key、Value 则是编码器的输出。

下面,我们来看一下解码器的 python 代码实现。
# code implementation of DECODER
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.masked_self_attention = MultiHeadAttention(d_model, num_heads)
self.enc_dec_attention = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# Masked self-attention layer
self_attention_output= self.masked_self_attention(x, x, x, tgt_mask)
self_attention_output = self.dropout(self_attention_output)
x = x + self_attention_output
x = self.norm1(x)
# Encoder-decoder attention layer
enc_dec_attention_output= self.enc_dec_attention(x, encoder_output,
encoder_output, src_mask)
enc_dec_attention_output = self.dropout(enc_dec_attention_output)
x = x + enc_dec_attention_output
x = self.norm2(x)
# Feed-forward layer
feed_forward_output = self.feed_forward(x)
feed_forward_output = self.dropout(feed_forward_output)
x = x + feed_forward_output
x = self.norm3(x)
return x
# Define the DecoderLayer parameters
d_model = 512 # Dimensionality of the model
num_heads = 8 # Number of attention heads
d_ff = 2048 # Dimensionality of the feed-forward network
dropout = 0.1 # Dropout probability
batch_size = 1 # Batch Size
max_len = 100 # Max length of Sequence
# Define the DecoderLayer instance
decoder_layer = DecoderLayer(d_model, num_heads, d_ff, dropout)
src_mask = torch.rand(batch_size, max_len, max_len) > 0.5
tgt_mask = torch.tril(torch.ones(max_len, max_len)).unsqueeze(0) == 0
# Pass the input tensors through the DecoderLayer
output = decoder_layer(input_sequence, encoder_output, src_mask, tgt_mask)
# Output shape
print("Output shape:", output.shape)
5.线性层和softmax
Decoder 最终的输出是一个向量,其中每个元素是浮点数。我们怎么把这个向量转换为单词呢?这是线性层和softmax完成的。
线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为 logits 向量。假设我们的模型有 10000 个英语单词(模型的输出词汇表),此 logits 向量便会有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。

到目前位置,Transformer 模型的所有模块都已经介绍完毕。
接下来,我们将编码器、解码器、注意力机制、位置编码和前馈网络的知识结合起来,以了解完整的 Transformer 模型的结构和功能。
Transformer 模型概述
Transformer 模型的核心是堆叠在一起的编码器和解码器模块,用于处理输入序列并生成输出序列。以下是该架构的高级概述。

编码器
- 编码器模块处理输入序列,提取特征并创建输入的丰富表示。
- 它包含多个编码器层,每个层包含自注意机制和前馈网络。
- 自注意力机制允许模型同时关注输入序列的不同部分,捕捉依赖关系和关系。
- 我们向输入嵌入添加位置编码,以提供有关序列中标记位置的信息。
解码器
- 解码器模块将编码器的输出作为输入并生成输出序列。
- 与编码器一样,它由多个解码器层组成,每个解码器层包含自注意力、编码器-解码器注意力和前馈网络。
- 除了自注意力之外,解码器还结合了编码器-解码器注意力来在生成输出的同时关注输入序列。
- 与编码器类似,我们向输入嵌入添加位置编码以提供位置信息。
残差连接和层规范化
- 在编码器和解码器模块的每一层之间,残差连接都遵循层规范化。
- 这些机制促进了梯度在网络中的流动,并有助于稳定训练。
完整的 Transformer 模型由多个编码器和解码器层堆叠而成。每层独立处理输入序列,使模型能够学习分层表示并捕获数据中的复杂模式。编码器将其输出传递给解码器,解码器根据输入生成最终输出序列。
接下来,让我们用 Python 实现完整的 Transformer 模型。
# implementation of TRANSFORMER
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff,
max_len, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_len)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)])
self.linear = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
encoder_embedding = self.encoder_embedding(src)
en_positional_encoding = self.positional_encoding(encoder_embedding)
src_embedded = self.dropout(en_positional_encoding)
decoder_embedding = self.decoder_embedding(tgt)
de_positional_encoding = self.positional_encoding(decoder_embedding)
tgt_embedded = self.dropout(de_positional_encoding)
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.linear(dec_output)
return output
# Example usecase
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_len = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers,
d_ff, max_len, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (5, max_len)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (5, max_len)) # (batch_size, seq_length)
transformer(src_data, tgt_data[:, :-1]).shape
模型的训练与评估
训练 Transformer 模型涉及优化其参数以最小化损失函数,通常使用梯度下降和反向传播。训练完成后,将使用各种指标评估模型的性能,以评估其解决目标任务的有效性。
训练过程
- 梯度下降和反向传播:
- 在训练期间,输入序列被输入到模型中,并生成输出序列。
- 使用损失函数(例如交叉熵损失)来衡量预测值和实际值之间的差异。
- 梯度下降用于在最小化损失的方向上更新模型的参数。
-
优化器根据这些梯度调整参数,并迭代更新它们以提高模型性能。
-
学习率调度:
- 可以采用学习率调度技术来动态调整训练期间的学习率。
- 常见的策略包括热身计划,其中学习率从较低开始并逐渐增加,以及衰减计划,其中学习率随着时间的推移而降低。
评估指标
- 困惑度
- 困惑度是用来评估语言模型(包括 Transformers)性能的常用指标。
-
它衡量模型预测给定标记序列的准确性。
-
BLEU 得分
- BLEU(双语评估测试)分数通常用于评估机器翻译文本的质量。
- 它将生成的翻译与人工翻译提供的一个或多个参考翻译进行比较。
- BLEU 分数范围从 0 到 1,分数越高,翻译质量越好。
下面是使用 PyTorch 进行训练和评估 Transformer 模型的基本代码实现。
# training and evaluation of transformer model
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
# Training loop
transformer.train()
for epoch in range(10):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:]
.contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}: Loss= {loss.item():.4f}")
#Dummy Data
src_data = torch.randint(1, src_vocab_size, (5, max_len)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (5, max_len)) # (batch_size, seq_length)
# Evaluation loop
transformer.eval()
with torch.no_grad():
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:]
.contiguous().view(-1))
print(f"\nEvaluation Loss for dummy data= {loss.item():.4f}")